

#8 The CrowdStrike Disaster
(October 2024)
This column covers the largest and most expensive IT outage in history: the CrowdStrike disaster. This article dives a bit deeper into enterprise cybersecurity concepts and also provides a great example of how a single seemingly innocuous mistake caused over $10 billion in global damages within a short amount of time. Before we get into the details, let's cover the basics first:
What is CrowdStrike?
CrowdStrike was founded in 2011 by George Kurtz, Dmitri Alperovitch and Gregg Marston. The company's origins are rooted in the founders' extensive experience in the cybersecurity industry, with Kurtz previously serving as the CTO at McAfee and Alperovitch also having worked there. They established CrowdStrike in response to what they perceived as a significant gap in the market: the need for more effective solutions against advanced persistent threats (APTs) and state-sponsored attacks.
From its inception, CrowdStrike took an innovative approach by focusing on cloud-native solutions, a relatively uncommon approach in the endpoint security space at the time. This strategy allowed for greater scalability and flexibility in their offerings. Initially, the company concentrated on providing incident response and proactive threat-hunting services, leveraging the founders' expertise in tracking sophisticated and evolving threat actors.
CrowdStrike's profile in the cybersecurity world rose significantly in 2014 when they published a report linking cyber attacks against Western energy companies to the Russian government. This report, along with their involvement in investigating other high-profile incidents, such as the 2016 Democratic National Committee email leak, helped establish their reputation as a leading cybersecurity firm. The company's innovative approach, coupled with the increasing importance of cybersecurity in the digital age, fueled rapid growth. CrowdStrike attracted substantial venture capital funding and eventually went public (CRWD) with a successful IPO on the NASDAQ in 2019, solidifying its position as a major player in the cybersecurity industry.
What services do they offer?
CrowdStrike's Falcon platform is a comprehensive cybersecurity solution that provides endpoint protection, threat intelligence and incident response services:
- Endpoint Protection: Falcon protects devices (endpoints) like computers, servers and mobile devices from various cyber threats.
- Threat Intelligence: Via Falcon, CrowdStrike gathers and analyzes data on cyber threats from around the world, helping organizations stay informed about potential risks.
- Incident Response: The Falcon platform also provides services to help organizations respond to and recover from cyber attacks.
- Managed Hunting: Their team of security experts actively searches for threats that might have evaded automated defenses.
- Cloud Security: They offer solutions to protect cloud-based infrastructure and applications.
- Identity Protection: CrowdStrike provides tools to secure user identities and prevent unauthorized access.
- Log Management and Analysis: They help organizations collect, store and analyze log data for security purposes.
What is Falcon (Endpoint Protection), and why is it at the heart of this incident?
One of the key components of the Falcon platform is its sensor detection technology.
The Falcon sensor is a lightweight agent (application) that is installed on endpoints, such as servers, desktops and laptops. The sensor continuously monitors the endpoint for suspicious activities and behaviors, using a combination of advanced machine learning algorithms, behavioral analysis and threat intelligence. When the sensor detects a potential threat, it immediately sends an alert to the Falcon platform, which analyzes the threat and provides guidance on how to respond.
So what happened on July 19, 2024?
Early on the morning of July 19th, CrowdStrike issued a routine configuration update of the Falcon sensor. This update, however, contained a serious flaw. When the update was installed on Windows systems running the Falcon software, it caused a critical error in the Windows operating system. This error made the affected devices either get stuck in a loop of repeatedly restarting (otherwise known as a bootloop) or booting up into a special recovery mode typically used for fixing problems.
The actual issue with the configuration was a fundamental computer science no-no, which we will dive into later in this newsletter.
As a result, ~8.5 million Windows computers and servers in businesses, government agencies, hospitals and other organizations around the world suddenly stopped working properly. CrowdStrike quickly realized the problem was caused by their update and worked to fix it, but it took time to distribute the fix and get all the affected computers working again.
How bad was the damage?
The damage from the resulting outage was staggering, with companies and users across the world impacted.
- Over 5,000 flights were canceled globally with cancellations continuing through the following week. Airlines such as Qantas, Virgin Australia, Jetstar, Cathay Pacific, Delta, United and American Airlines experienced system failures, leading to grounded flights, delays and chaos at airports. Delta Airlines was hit particularly hard with over $500 million in losses.
- The healthcare sector also faced severe challenges, with hospitals forced to postpone non-urgent surgeries and appointments due to the inability to access patient records. Many hospitals were forced to enact emergency plans that are normally reserved for severe disasters, including paper charting of medical information.
- Government agencies, such as the U.S. Department of Homeland Security and NASA, reported disruptions, while emergency services like 911 were affected in several U.S. states.
The economic ramifications of the incident were substantial, with estimates suggesting that the top 500 U.S. companies alone faced financial losses of approximately $5.4 billion. Worldwide, the damages are projected to be over $10.4 billion. CrowdStrike's stock price plummeted by more than 11 percent on the day of the outage and over 36 percent the following week.
Was there any impact to JPMorganChase and the financial services industry?
The impact was felt across major financial hubs, including Hong Kong, Dubai, South Africa and London, as bankers and employees struggled to cope with the fallout from the outage.
Many prominent banks, including JPMorgan Chase, Nomura Holdings, Bank of America and Haitong Securities, were hit very hard. Employees were unable to access desktop systems, facing blue error screens when trying to log in. Even if employees were able to log in, backend applications making use of Windows Server were still down. This lack of access to critical applications and data severely hindered the ability to carry out daily responsibilities, and many employees simply went home.
The trading sector was among the most severely affected by the outage. Trading desks at some institutions, like Haitong Securities, were paralyzed for hours due to the system failures. This likely resulted in substantial losses for the banks, as traders were unable to execute transactions.
What are the lessons learned?
This incident underscores the critical importance of robust IT infrastructure, comprehensive risk management practices and effective contingency plans in the banking sector. As financial institutions increasingly depend on technology to power their operations and services, any software glitches, system failures or vendor-related issues can have far-reaching consequences – impacting trading activities, customer services and overall business continuity.
The outage also raises concerns about the systemic risks associated with the growing reliance on third-party technology providers in the financial industry. When multiple major banks rely on the same vendor for critical services, any disruption at the vendor level can have a cascading effect across the sector. This calls for enhanced due diligence, rigorous vendor management practices and regular testing of backup systems to mitigate such risks.
Congratulations on making it this far!
A deeper look at the Out of Bounds error:
In this short section, we’ll take a brief look at some fundamental computer science concepts and map them to the error that caused this mess. These concepts are taught in most Intro to Programming courses.
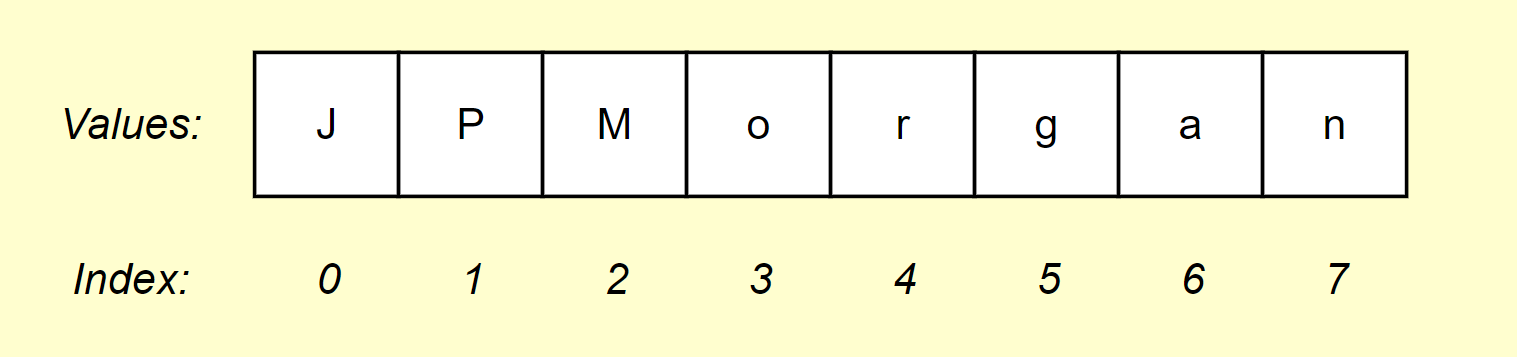
- Array: An array is a collection of items (alphabet characters, for example) stored in contiguous memory locations within the computer, allowing quick access to elements using a numeric index.
- Index: An array index is a numeric position that identifies and accesses a specific element within an array, starting from zero for the first element.
We can visually represent an array, the values within the array and the numeric index like this:
The CrowdStrike incident was caused when a call was made to access a part of an array or other similar data structure that didn’t exist.
The below image demonstrates what happens when we correctly access an element in the array, and what happens when we don’t.
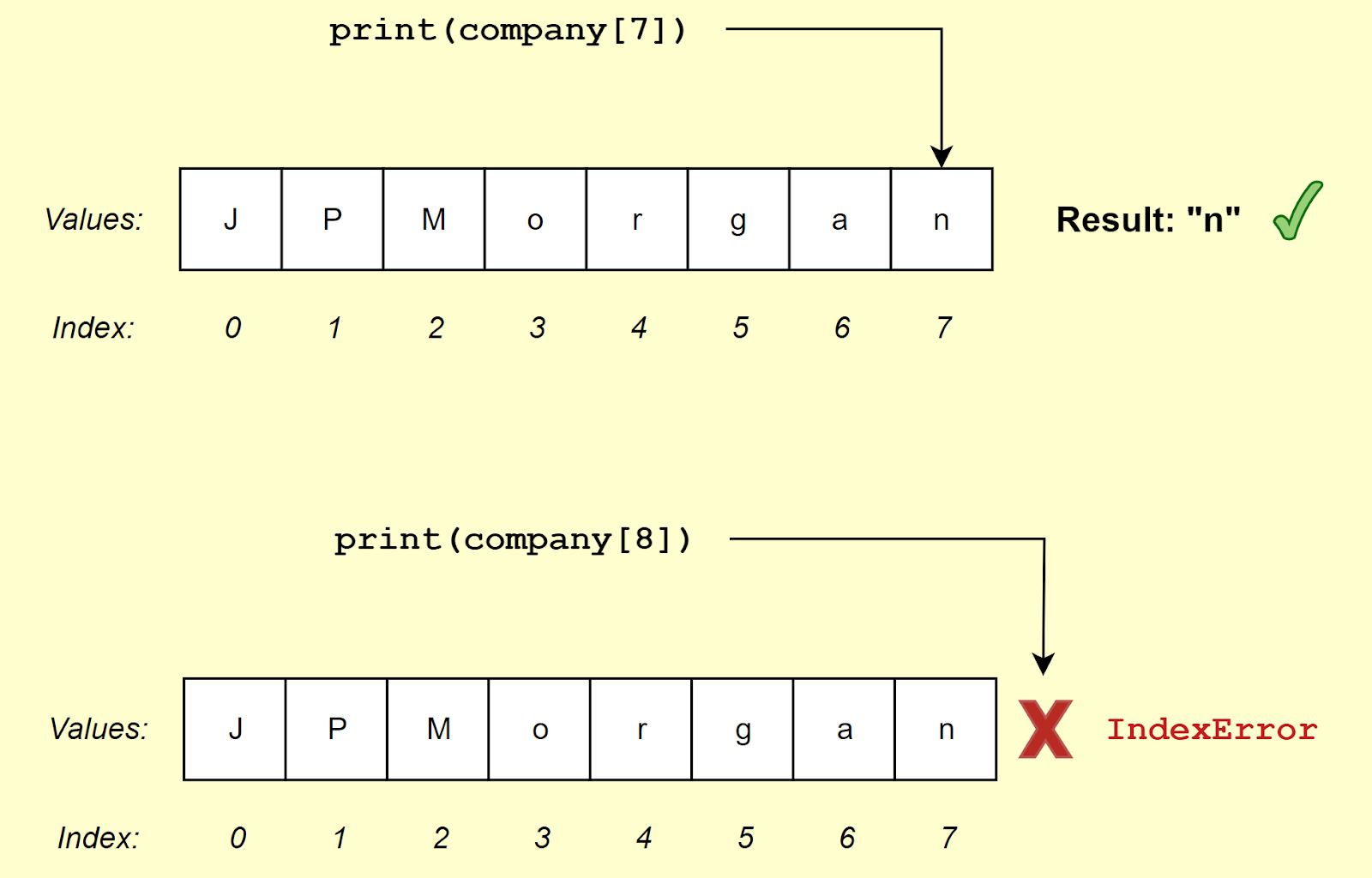
In this example, I’m using Python, and an IndexError will crash the program.
A good developer will recognize when there’s a chance an error will be thrown and write something called a try-catch block. This is best illustrated with the following Python pseudocode:
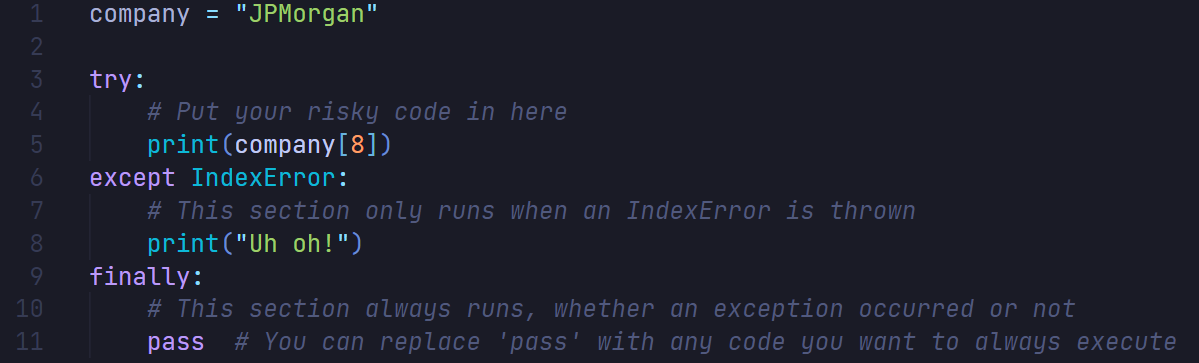
Try-catch blocks are primarily used to handle potential errors or exceptions in code without causing the entire program to crash. They allow developers to anticipate problematic scenarios and provide alternative paths or graceful error handling when things go wrong. Common use cases include file operations, network requests, user input processing and any situation where external factors or unpredictable data could lead to runtime errors.
Do you have a question or idea for a future column? Please contact: chasealumtech@gmail.com and/or fill out this survey. Thank you!
___________________________________________________________________________________
Links to Prior CAA Tech Corner Columns
#4 Anatomy of a Modern Credit Card
#5 How to Whitelist an Email Address
#6 Multi-Factor Authentification
About Dan Alvarez

Dan Alvarez began at JPMorgan Chase in June 2016 as a summer technology analyst/ infrastructure engineer, and left in April 2022 as a Senior Software Engineer in Global Technology Infrastructure - Product Strategy and Site Reliability Engineering (SRE). Since May 2022, he has worked for Amazon Web Services as an Enterprise Solutions Architect.
He is also an avid guest lecturer for the City University of New York and has given lectures on artificial intelligence, cloud computing and career progression. Dan also works closely with Amazon's Skills to Jobs team and the NY Tech Alliance with the goal of creating the most diverse, equitable and accessible tech ecosystem in the world.
A graduate of Brooklyn College, he is listed as an Alumni Champion of the school and was named one of Brooklyn College's 30 Under 30. He lives in Bensonhurst, Brooklyn.
----------------------------------
Comments?
Send them to chasealumtech@gmail.com.